はじめに
Elasticsearchでは、SQLでいうところのGROUP BYに近い挙動となるAggregationsというクエリがあります。
ここ何回かの過去記事でもAggregationsをちょいと雑に俯瞰する記事を投稿しました。
itdepends.hateblo.jp
なおこのAggregationsですが、GROUP BYに近いというものの、SQLでのGROUP BYと副問い合わせなどを駆使した「グループ内で最大値をとるレコードを抽出する」といったことは(私がモグリで見逃しているだけかもしれませんが)直接的な方法はありません。
検索エンジンの用法・用途としては、無理にこの仕組みはいらないな〜、少なくともその対応のために、新しいクエリのシンタックスを覚えたりするのはめんどくさいな〜と思いつつ、どうしても小手先のワザで済ませたい場合のある手法の一例を共有します。
途中はさみこむワザはやや邪道かもしれませんが、はからずもAggregationsのシンタックスや挙動を深く理解することにもつながるかもしれませんので、記事にしてみた次第です。
考え方
具体的なアイディアの土台としては、次の図のように、「ドキュメントの中にそのドキュメントを象徴する複合項目(図では「サマリ」項目と呼びました)を再掲」しておき、そこにからめて所定のAggregationsをかませる、です。
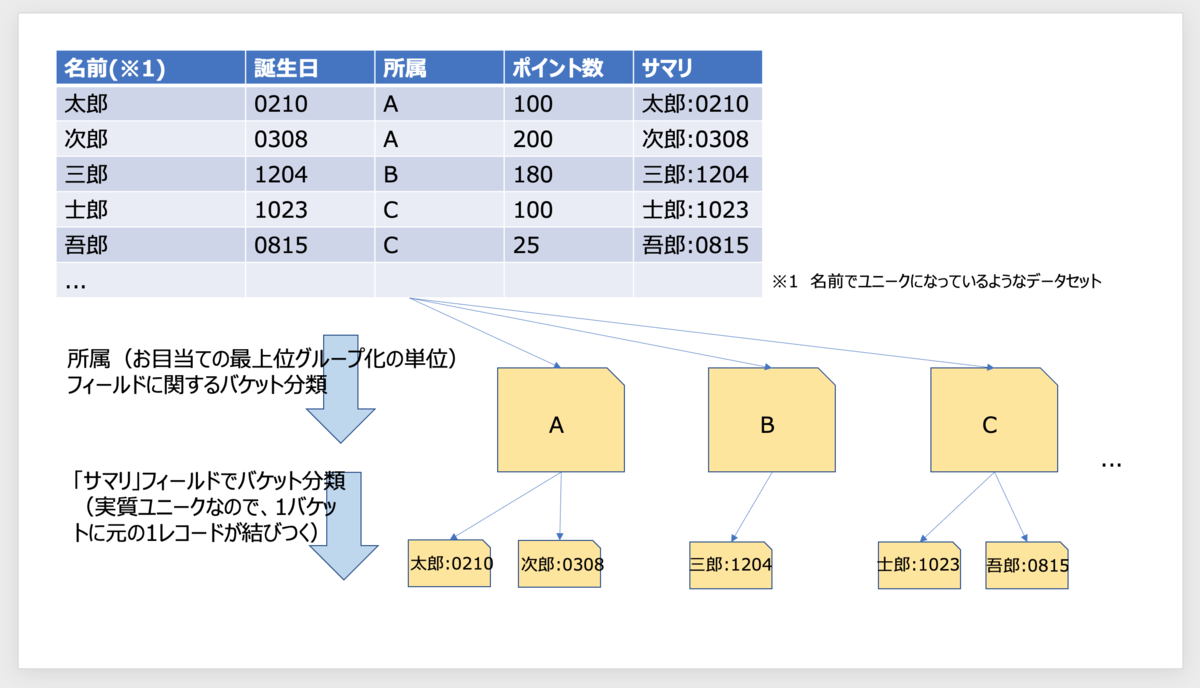
ま、それでいいなら可能だよなと思った方、ごめんなさい。先に謝っておきます。
お、邪道だけどアリかもと思っていただいた方ありがとうございます。もちろん、いろいろと効率が悪いというか目的外使用の側面はあると思いますので、ご利用時はパフォーマンス含めご注意ください。
なお、サマリ項目と言えば、runtime_mappingという動的にAggregationの対象フィールドを擬似的に生成するオプションが7.x系で追加になっているようです。
もちろん他の用途をイメージしたものだと思いますが、「サマリ」フィールドをインデックス時に考えなくて良いという本手法の選択肢が増えたといえるかもしれません。
本記事は6.8系で確認した都合、runtime_mappingの説明は含めていませんが、そもそも本記事の邪道用途に限らずおもしろい仕掛けなのでご紹介しておきます。
www.elastic.co
Runtime fields | Elasticsearch Guide [7.13] | Elastic
ということで以下事例です。
データインポート
ちょっと冗長ですが、以下のデータを入れてみてください。
※直接使うのは、aフィールド、dフィールド、そして上の方で、便宜上「サマリ」フィールドと呼称したものに該当するのが、complフィールドです。
aフィールド(のちの例では「a.keyword」となります)でグループ化すると5グループで、うち4グループは配下に5件、1グループだけ6件となるようなデータ群です。
POST a_ex/_doc/
{"a": "a10", "b": 10, "c": 20, "compl": "a10:10:0", "d": 0, "weight": 1, "loc": {"lat": 35.5, "lon": 145.1}, "date": "2021-07-01"}
POST a_ex/_doc/
{"a": "a10", "b": 10, "c": 20, "compl": "a10:10:1", "d": 1, "weight": 1, "loc": {"lat": 35.5, "lon": 145.1}, "date": "2021-07-01"}
POST a_ex/_doc/
{"a": "a10", "b": 10, "c": 20, "compl": "a10:10:2", "d": 2, "weight": 1, "loc": {"lat": 35.5, "lon": 145.1}, "date": "2021-07-01"}
POST a_ex/_doc/
{"a": "a10", "b": 10, "c": 20, "compl": "a10:10:3", "d": 3, "weight": 1, "loc": {"lat": 35.5, "lon": 145.1}, "date": "2021-07-01"}
POST a_ex/_doc/
{"a": "a10", "b": 10, "c": 20, "compl": "a10:10:4", "d": 4, "weight": 1, "loc": {"lat": 35.5, "lon": 145.1}, "date": "2021-07-01"}
POST a_ex/_doc/
{"a": "a100", "b": 100, "c": 200, "compl": "a100:100:1000", "d": 5, "weight": 2, "loc": {"lat": 35.5, "lon": 145.2}, "date": "2021-07-02"}
POST a_ex/_doc/
{"a": "a100", "b": 100, "c": 200, "compl": "a100:100:1001", "d": 6, "weight": 2, "loc": {"lat": 35.5, "lon": 145.2}, "date": "2021-07-02"}
POST a_ex/_doc/
{"a": "a100", "b": 100, "c": 200, "compl": "a100:100:1002", "d": 7, "weight": 2, "loc": {"lat": 35.5, "lon": 145.2}, "date": "2021-07-02"}
POST a_ex/_doc/
{"a": "a100", "b": 100, "c": 200, "compl": "a100:100:1003", "d": 8, "weight": 2, "loc": {"lat": 35.5, "lon": 145.2}, "date": "2021-07-02"}
POST a_ex/_doc/
{"a": "a100", "b": 100, "c": 200, "compl": "a100:100:1004", "d": 9, "weight": 2, "loc": {"lat": 35.5, "lon": 145.2}, "date": "2021-07-02"}
POST a_ex/_doc/
{"a": "a1000", "b": 1000, "c": 2000, "compl": "a1000:1000:2000", "d": 10, "weight": 3, "loc": {"lat": 35.5, "lon": 145.3}, "date": "2021-07-03"}
POST a_ex/_doc/
{"a": "a1000", "b": 1000, "c": 2000, "compl": "a1000:1000:2001", "d": 11, "weight": 3, "loc": {"lat": 35.5, "lon": 145.3}, "date": "2021-07-03"}
POST a_ex/_doc/
{"a": "a1000", "b": 1000, "c": 2000, "compl": "a1000:1000:2002", "d": 12, "weight": 3, "loc": {"lat": 35.5, "lon": 145.3}, "date": "2021-07-03"}
POST a_ex/_doc/
{"a": "a1000", "b": 1000, "c": 2000, "compl": "a1000:1000:2003", "d": 13, "weight": 3, "loc": {"lat": 35.5, "lon": 145.3}, "date": "2021-07-03"}
POST a_ex/_doc/
{"a": "a1000", "b": 1000, "c": 2000, "compl": "a1000:1000:2004", "d": 14, "weight": 3, "loc": {"lat": 35.5, "lon": 145.3}, "date": "2021-07-03"}
POST a_ex/_doc/
{"a": "a10000", "b": 10000, "c": 20000, "compl": "a10000:10000:3000", "d": 15, "weight": 4, "loc": {"lat": 35.5, "lon": 145.4}, "date": "2021-07-04"}
POST a_ex/_doc/
{"a": "a10000", "b": 10000, "c": 20000, "compl": "a10000:10000:3001", "d": 16, "weight": 4, "loc": {"lat": 35.5, "lon": 145.4}, "date": "2021-07-04"}
POST a_ex/_doc/
{"a": "a10000", "b": 10000, "c": 20000, "compl": "a10000:10000:3002", "d": 17, "weight": 4, "loc": {"lat": 35.5, "lon": 145.4}, "date": "2021-07-04"}
POST a_ex/_doc/
{"a": "a10000", "b": 10000, "c": 20000, "compl": "a10000:10000:3003", "d": 18, "weight": 4, "loc": {"lat": 35.5, "lon": 145.4}, "date": "2021-07-04"}
POST a_ex/_doc/
{"a": "a10000", "b": 10000, "c": 20000, "compl": "a10000:10000:3004", "d": 19, "weight": 4, "loc": {"lat": 35.5, "lon": 145.4}, "date": "2021-07-04"}
POST a_ex/_doc/
{"a": "a100000", "b": 100000, "c": 200000, "compl": "a100000:100000:4000", "d": 20, "weight": 5, "loc": {"lat": 35.5, "lon": 145.5}, "date": "2021-07-05"}
POST a_ex/_doc/
{"a": "a100000", "b": 100000, "c": 200000, "compl": "a100000:100000:4001", "d": 21, "weight": 5, "loc": {"lat": 35.5, "lon": 145.5}, "date": "2021-07-05"}
POST a_ex/_doc/
{"a": "a100000", "b": 100000, "c": 200000, "compl": "a100000:100000:4002", "d": 22, "weight": 5, "loc": {"lat": 35.5, "lon": 145.5}, "date": "2021-07-05"}
POST a_ex/_doc/
{"a": "a100000", "b": 100000, "c": 200000, "compl": "a100000:100000:4003", "d": 23, "weight": 5, "loc": {"lat": 35.5, "lon": 145.5}, "date": "2021-07-05"}
POST a_ex/_doc/
{"a": "a100000", "b": 100000, "c": 200000, "compl": "a100000:100000:4004", "d": 24, "weight": 5, "loc": {"lat": 35.5, "lon": 145.5}, "date": "2021-07-05"}
POST a_ex/_doc/
{"a": "a100000", "b": 100000, "c": 200000, "compl": "a100000:100000:9999", "d": 24, "weight": 5, "loc": {"lat": 35.5, "lon": 145.5}, "date": "2021-07-05"}
1. グループごとの擬似レコード一覧(ウォーミングアップ)
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword",
"size": 3
}
}
}
}
}
}
結果
aフィールドでグループ化しつつ、実質ユニークなフィールドcomplでサブグループ化するので配下の一覧が得られます。
(ここでは、全件ではなく、(結果的に)DB出現順に3件ずつ取得しています。)
{
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3,
"buckets" : [
{
"key" : "a100000:100000:4000",
"doc_count" : 1
},
{
"key" : "a100000:100000:4001",
"doc_count" : 1
},
{
"key" : "a100000:100000:4002",
"doc_count" : 1
}
]
}
},
{
"key" : "a10",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2,
"buckets" : [
{
"key" : "a10:10:0",
"doc_count" : 1
},
{
"key" : "a10:10:1",
"doc_count" : 1
},
{
"key" : "a10:10:2",
"doc_count" : 1
}
]
}
},
{
"key" : "a100",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2,
"buckets" : [
{
"key" : "a100:100:1000",
"doc_count" : 1
},
{
"key" : "a100:100:1001",
"doc_count" : 1
},
{
"key" : "a100:100:1002",
"doc_count" : 1
}
]
}
},
{
"key" : "a1000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2,
"buckets" : [
{
"key" : "a1000:1000:2000",
"doc_count" : 1
},
{
"key" : "a1000:1000:2001",
"doc_count" : 1
},
{
"key" : "a1000:1000:2002",
"doc_count" : 1
}
]
}
},
{
"key" : "a10000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2,
"buckets" : [
{
"key" : "a10000:10000:3000",
"doc_count" : 1
},
{
"key" : "a10000:10000:3001",
"doc_count" : 1
},
{
"key" : "a10000:10000:3002",
"doc_count" : 1
}
]
}
}
]
}
}
}
2. あるフィールド値の合計がある値以上のグループに限定した擬似レコード一覧
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword",
"size": 3
}
},
"the_sum": {
"sum": {
"field": "b"
}
},
"my_selection": {
"bucket_selector": {
"buckets_path": {
"p": "the_sum"
},
"script": "params.p > 5000"
}
}
}
}
}
}
bucket_selectorを使って、合計が5000より大きいグループのみに限定しています。
今回のデータの場合、a10000とa100000のグループのみ抽出されます。
結果
{
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 3,
"buckets" : [
{
"key" : "a100000:100000:4000",
"doc_count" : 1
},
{
"key" : "a100000:100000:4001",
"doc_count" : 1
},
{
"key" : "a100000:100000:4002",
"doc_count" : 1
}
]
},
"the_sum" : {
"value" : 600000.0
}
},
{
"key" : "a10000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 2,
"buckets" : [
{
"key" : "a10000:10000:3000",
"doc_count" : 1
},
{
"key" : "a10000:10000:3001",
"doc_count" : 1
},
{
"key" : "a10000:10000:3002",
"doc_count" : 1
}
]
},
"the_sum" : {
"value" : 50000.0
}
}
]
}
}
}
3. 配下件数が多いグループのみ擬似一覧抽出
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword"
}
},
"count": {
"value_count": {
"field": "b"
}
},
"myfilter": {
"bucket_selector": {
"buckets_path": {
"c": "count"
},
"script": "params.c > 5"
}
}
}
}
}
}
結果
グループ配下のレコード数が5より大のものが抽出されるので、6件レコードがある、a100000グループの配下の6件が抽出されます。
{
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000:100000:4000",
"doc_count" : 1
},
{
"key" : "a100000:100000:4001",
"doc_count" : 1
},
{
"key" : "a100000:100000:4002",
"doc_count" : 1
},
{
"key" : "a100000:100000:4003",
"doc_count" : 1
},
{
"key" : "a100000:100000:4004",
"doc_count" : 1
},
{
"key" : "a100000:100000:9999",
"doc_count" : 1
}
]
},
"count" : {
"value" : 6
}
}
]
}
}
}
4. グループごとにグループ配下の擬似レコードと特定フィールドをペアで抜き出し(sumは実際は1件のレコードの合計なので1つの値を抽出)
おさらい1
complフィールドが実質ユニークなので、そのサブAggsのさらにサブサブAggsで合計を取得すると実際は1件のレコードのあるフィールドの合計つまり値そのものなので、そのような取得を行ってみます。邪道感が増しますが、実質ユニークフィールドに固めた項目以外の項目が欲しい場合とともに、次項のクエリの下敷きの例となっています。
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword"
},
"aggs": {
"dValue": {
"sum": {
"field": "d"
}
}
}
}
}
}
}
}
結果
{
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000:100000:4000",
"doc_count" : 1,
"dValue" : {
"value" : 20.0
}
},
{
"key" : "a100000:100000:4001",
"doc_count" : 1,
"dValue" : {
"value" : 21.0
}
},
{
"key" : "a100000:100000:4002",
"doc_count" : 1,
"dValue" : {
"value" : 22.0
}
},
{
"key" : "a100000:100000:4003",
"doc_count" : 1,
"dValue" : {
"value" : 23.0
}
},
{
"key" : "a100000:100000:4004",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
},
{
"key" : "a100000:100000:9999",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
}
]
}
},
{
"key" : "a10",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10:10:0",
"doc_count" : 1,
"dValue" : {
"value" : 0.0
}
},
{
"key" : "a10:10:1",
"doc_count" : 1,
"dValue" : {
"value" : 1.0
}
},
{
"key" : "a10:10:2",
"doc_count" : 1,
"dValue" : {
"value" : 2.0
}
},
{
"key" : "a10:10:3",
"doc_count" : 1,
"dValue" : {
"value" : 3.0
}
},
{
"key" : "a10:10:4",
"doc_count" : 1,
"dValue" : {
"value" : 4.0
}
}
]
}
},
{
"key" : "a100",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100:100:1000",
"doc_count" : 1,
"dValue" : {
"value" : 5.0
}
},
{
"key" : "a100:100:1001",
"doc_count" : 1,
"dValue" : {
"value" : 6.0
}
},
{
"key" : "a100:100:1002",
"doc_count" : 1,
"dValue" : {
"value" : 7.0
}
},
{
"key" : "a100:100:1003",
"doc_count" : 1,
"dValue" : {
"value" : 8.0
}
},
{
"key" : "a100:100:1004",
"doc_count" : 1,
"dValue" : {
"value" : 9.0
}
}
]
}
},
{
"key" : "a1000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a1000:1000:2000",
"doc_count" : 1,
"dValue" : {
"value" : 10.0
}
},
{
"key" : "a1000:1000:2001",
"doc_count" : 1,
"dValue" : {
"value" : 11.0
}
},
{
"key" : "a1000:1000:2002",
"doc_count" : 1,
"dValue" : {
"value" : 12.0
}
},
{
"key" : "a1000:1000:2003",
"doc_count" : 1,
"dValue" : {
"value" : 13.0
}
},
{
"key" : "a1000:1000:2004",
"doc_count" : 1,
"dValue" : {
"value" : 14.0
}
}
]
}
},
{
"key" : "a10000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10000:10000:3000",
"doc_count" : 1,
"dValue" : {
"value" : 15.0
}
},
{
"key" : "a10000:10000:3001",
"doc_count" : 1,
"dValue" : {
"value" : 16.0
}
},
{
"key" : "a10000:10000:3002",
"doc_count" : 1,
"dValue" : {
"value" : 17.0
}
},
{
"key" : "a10000:10000:3003",
"doc_count" : 1,
"dValue" : {
"value" : 18.0
}
},
{
"key" : "a10000:10000:3004",
"doc_count" : 1,
"dValue" : {
"value" : 19.0
}
}
]
}
}
]
}
}
}
5. グループ内であるフィールド値が最大の擬似レコードを抽出(件名に対応した例)
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword"
},
"aggs": {
"dValue": {
"sum": {
"field": "d"
}
}
}
},
"max_record": {
"max_bucket": {
"buckets_path": "c_list>dValue"
}
}
}
}
}
}
結果
max_recordという戻り値フィールドに注目!
{
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000:100000:4000",
"doc_count" : 1,
"dValue" : {
"value" : 20.0
}
},
{
"key" : "a100000:100000:4001",
"doc_count" : 1,
"dValue" : {
"value" : 21.0
}
},
{
"key" : "a100000:100000:4002",
"doc_count" : 1,
"dValue" : {
"value" : 22.0
}
},
{
"key" : "a100000:100000:4003",
"doc_count" : 1,
"dValue" : {
"value" : 23.0
}
},
{
"key" : "a100000:100000:4004",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
},
{
"key" : "a100000:100000:9999",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
}
]
},
"max_record" : {
"value" : 24.0,
"keys" : [
"a100000:100000:4004",
"a100000:100000:9999"
]
}
},
{
"key" : "a10",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10:10:0",
"doc_count" : 1,
"dValue" : {
"value" : 0.0
}
},
{
"key" : "a10:10:1",
"doc_count" : 1,
"dValue" : {
"value" : 1.0
}
},
{
"key" : "a10:10:2",
"doc_count" : 1,
"dValue" : {
"value" : 2.0
}
},
{
"key" : "a10:10:3",
"doc_count" : 1,
"dValue" : {
"value" : 3.0
}
},
{
"key" : "a10:10:4",
"doc_count" : 1,
"dValue" : {
"value" : 4.0
}
}
]
},
"max_record" : {
"value" : 4.0,
"keys" : [
"a10:10:4"
]
}
},
{
"key" : "a100",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100:100:1000",
"doc_count" : 1,
"dValue" : {
"value" : 5.0
}
},
{
"key" : "a100:100:1001",
"doc_count" : 1,
"dValue" : {
"value" : 6.0
}
},
{
"key" : "a100:100:1002",
"doc_count" : 1,
"dValue" : {
"value" : 7.0
}
},
{
"key" : "a100:100:1003",
"doc_count" : 1,
"dValue" : {
"value" : 8.0
}
},
{
"key" : "a100:100:1004",
"doc_count" : 1,
"dValue" : {
"value" : 9.0
}
}
]
},
"max_record" : {
"value" : 9.0,
"keys" : [
"a100:100:1004"
]
}
},
{
"key" : "a1000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a1000:1000:2000",
"doc_count" : 1,
"dValue" : {
"value" : 10.0
}
},
{
"key" : "a1000:1000:2001",
"doc_count" : 1,
"dValue" : {
"value" : 11.0
}
},
{
"key" : "a1000:1000:2002",
"doc_count" : 1,
"dValue" : {
"value" : 12.0
}
},
{
"key" : "a1000:1000:2003",
"doc_count" : 1,
"dValue" : {
"value" : 13.0
}
},
{
"key" : "a1000:1000:2004",
"doc_count" : 1,
"dValue" : {
"value" : 14.0
}
}
]
},
"max_record" : {
"value" : 14.0,
"keys" : [
"a1000:1000:2004"
]
}
},
{
"key" : "a10000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10000:10000:3000",
"doc_count" : 1,
"dValue" : {
"value" : 15.0
}
},
{
"key" : "a10000:10000:3001",
"doc_count" : 1,
"dValue" : {
"value" : 16.0
}
},
{
"key" : "a10000:10000:3002",
"doc_count" : 1,
"dValue" : {
"value" : 17.0
}
},
{
"key" : "a10000:10000:3003",
"doc_count" : 1,
"dValue" : {
"value" : 18.0
}
},
{
"key" : "a10000:10000:3004",
"doc_count" : 1,
"dValue" : {
"value" : 19.0
}
}
]
},
"max_record" : {
"value" : 19.0,
"keys" : [
"a10000:10000:3004"
]
}
}
]
}
}
}
6. グループごとに配下レコードの特定項目の値の降順に並べて値を取得(前項の「sumは実際は1件だけの合計」方式の応用)
前項はmaxでしたが、こちらは特定のフィールドの値の順序で並べて取得の例です。
(降順にしてあります。ここでは動きを見るために、降順に3件取得にしました。)
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword"
},
"aggs": {
"dValue": {
"sum": {
"field": "d"
}
},
"orderby": {
"bucket_sort": {
"sort": [
{
"dValue": {
"order": "desc"
}
}
],
"size": 3
}
}
}
}
}
}
}
}
結果
{
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000:100000:4004",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
},
{
"key" : "a100000:100000:9999",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
},
{
"key" : "a100000:100000:4003",
"doc_count" : 1,
"dValue" : {
"value" : 23.0
}
}
]
}
},
{
"key" : "a10",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10:10:4",
"doc_count" : 1,
"dValue" : {
"value" : 4.0
}
},
{
"key" : "a10:10:3",
"doc_count" : 1,
"dValue" : {
"value" : 3.0
}
},
{
"key" : "a10:10:2",
"doc_count" : 1,
"dValue" : {
"value" : 2.0
}
}
]
}
},
{
"key" : "a100",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100:100:1004",
"doc_count" : 1,
"dValue" : {
"value" : 9.0
}
},
{
"key" : "a100:100:1003",
"doc_count" : 1,
"dValue" : {
"value" : 8.0
}
},
{
"key" : "a100:100:1002",
"doc_count" : 1,
"dValue" : {
"value" : 7.0
}
}
]
}
},
{
"key" : "a1000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a1000:1000:2004",
"doc_count" : 1,
"dValue" : {
"value" : 14.0
}
},
{
"key" : "a1000:1000:2003",
"doc_count" : 1,
"dValue" : {
"value" : 13.0
}
},
{
"key" : "a1000:1000:2002",
"doc_count" : 1,
"dValue" : {
"value" : 12.0
}
}
]
}
},
{
"key" : "a10000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10000:10000:3004",
"doc_count" : 1,
"dValue" : {
"value" : 19.0
}
},
{
"key" : "a10000:10000:3003",
"doc_count" : 1,
"dValue" : {
"value" : 18.0
}
},
{
"key" : "a10000:10000:3002",
"doc_count" : 1,
"dValue" : {
"value" : 17.0
}
}
]
}
}
]
}
}
}
7. レコードの特定項目の値が特定の値以上のものを取得(グループごとに分類あり)
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword"
},
"aggs": {
"dValue": {
"sum": {
"field": "d"
}
},
"myfilter": {
"bucket_selector": {
"buckets_path": {
"d": "dValue"
},
"script": "params.d >= 11"
}
}
}
}
}
}
}
}
結果
"aggregations" : {
"grp" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000",
"doc_count" : 6,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a100000:100000:4000",
"doc_count" : 1,
"dValue" : {
"value" : 20.0
}
},
{
"key" : "a100000:100000:4001",
"doc_count" : 1,
"dValue" : {
"value" : 21.0
}
},
{
"key" : "a100000:100000:4002",
"doc_count" : 1,
"dValue" : {
"value" : 22.0
}
},
{
"key" : "a100000:100000:4003",
"doc_count" : 1,
"dValue" : {
"value" : 23.0
}
},
{
"key" : "a100000:100000:4004",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
},
{
"key" : "a100000:100000:9999",
"doc_count" : 1,
"dValue" : {
"value" : 24.0
}
}
]
}
},
{
"key" : "a10",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
},
{
"key" : "a100",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ ]
}
},
{
"key" : "a1000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a1000:1000:2001",
"doc_count" : 1,
"dValue" : {
"value" : 11.0
}
},
{
"key" : "a1000:1000:2002",
"doc_count" : 1,
"dValue" : {
"value" : 12.0
}
},
{
"key" : "a1000:1000:2003",
"doc_count" : 1,
"dValue" : {
"value" : 13.0
}
},
{
"key" : "a1000:1000:2004",
"doc_count" : 1,
"dValue" : {
"value" : 14.0
}
}
]
}
},
{
"key" : "a10000",
"doc_count" : 5,
"c_list" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "a10000:10000:3000",
"doc_count" : 1,
"dValue" : {
"value" : 15.0
}
},
{
"key" : "a10000:10000:3001",
"doc_count" : 1,
"dValue" : {
"value" : 16.0
}
},
{
"key" : "a10000:10000:3002",
"doc_count" : 1,
"dValue" : {
"value" : 17.0
}
},
{
"key" : "a10000:10000:3003",
"doc_count" : 1,
"dValue" : {
"value" : 18.0
}
},
{
"key" : "a10000:10000:3004",
"doc_count" : 1,
"dValue" : {
"value" : 19.0
}
}
]
}
}
]
}
}
}
8. 複合クエリも可能
GET a_ex/_search?size=0&filter_path=agg*
{
"aggs": {
"grp": {
"terms": {
"field": "a.keyword"
},
"aggs": {
"c_list": {
"terms": {
"field": "compl.keyword"
},
"aggs": {
"dValue": {
"sum": {
"field": "d"
}
},
"f": {
"bucket_sort": {
"sort": [
{ "dValue": { "order": "desc" } }
],
"size": 3
}
}
}
},
"count": {
"value_count": {
"field": "b"
}
},
"myfilter": {
"bucket_selector": {
"buckets_path": {
"c": "count"
},
"script": "params.c > 5"
}
}
}
}
}
}

